|
I am Dong-Hwan Jang, a CS Ph.D. student at the University of Illinois Urbana-Champaign (UIUC). My research centers on video generation as a pathway to visual understanding. I develop methods for controllable synthesis—from reward-guided generation to 3D geometric priors for physical coherence. Longer-term, I aim to leverage the visual knowledge within generative models to advance visual reasoning and interaction. Before starting my Ph.D., I worked as an AI researcher at Samsung, where I researched OOD-robust fine-tuning techniques on domain-specific data. I earned my M.S. in Electrical and Computer Engineering from Seoul National University, where I was advised by Professor Bohyung Han, and also interned at NAVER AI Lab with Dongyoon Han and Sangdoo Yun. Email / CV / Google Scholar / X / Linkedin |

|
|
|
|
|
 
|
Onkar Kishor Susladkar, Dong-Hwan Jang, Tushar Prakash, Adheesh Sunil Juvekar, Vedant Shah, Ayush Barik, Nabeel Bashir, Muntasir Wahed, Ritish Shrirao, Ismini Lourentzou CVPR, 2026 RewardFlow is a zero-shot, training-free framework for text-guided image editing and generation using reward-guided Langevin dynamics. We steer pretrained diffusion and flow-matching models at inference with hierarchically designed coarse-to-fine differentiable rewards (e.g., a VQA-based reward for semantic supervision and a SAM-guided reward for localized edits), controlled by a prompt-aware adaptive policy. |
 
|
Onkar Kishor Susladkar, Tushar Prakash, Adheesh Sunil Juvekar, Kiet A. Nguyen, Dong-Hwan Jang, Inderjit S. Dhillon, Ismini Lourentzou CVPR, 2026 PyraTok is a language-aligned pyramidal tokenizer for video understanding and generation that learns discrete latents across multiple spatial-temporal resolutions. We introduce Language-aligned Pyramidal Quantization (LaPQ), discretizing encoder features at several depths with a shared large binary codebook. PyraTok achieves state-of-the-art video reconstruction, text-to-video quality, and zero-shot performance on segmentation, action localization, and understanding, scaling to 4K/8K resolutions. |
|
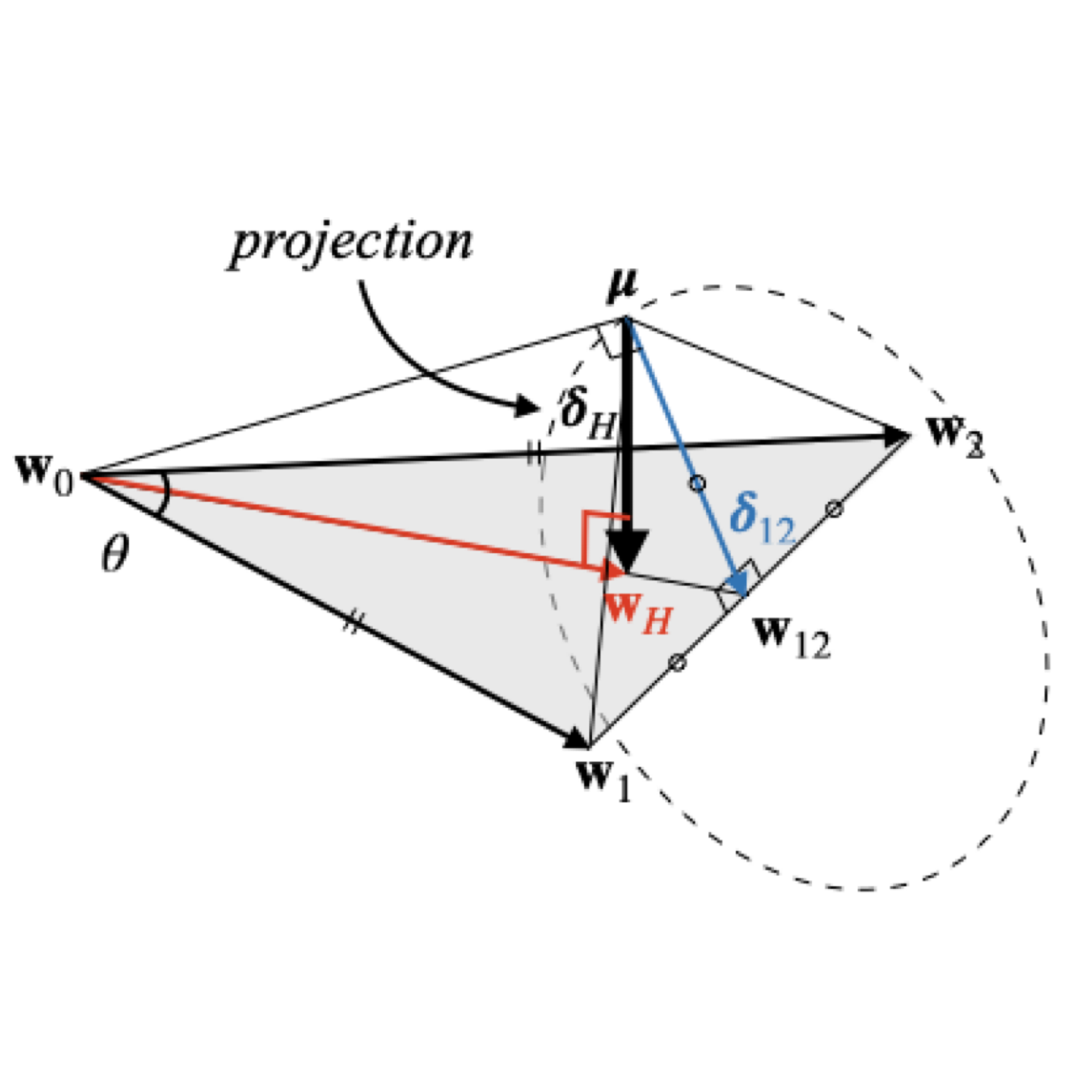
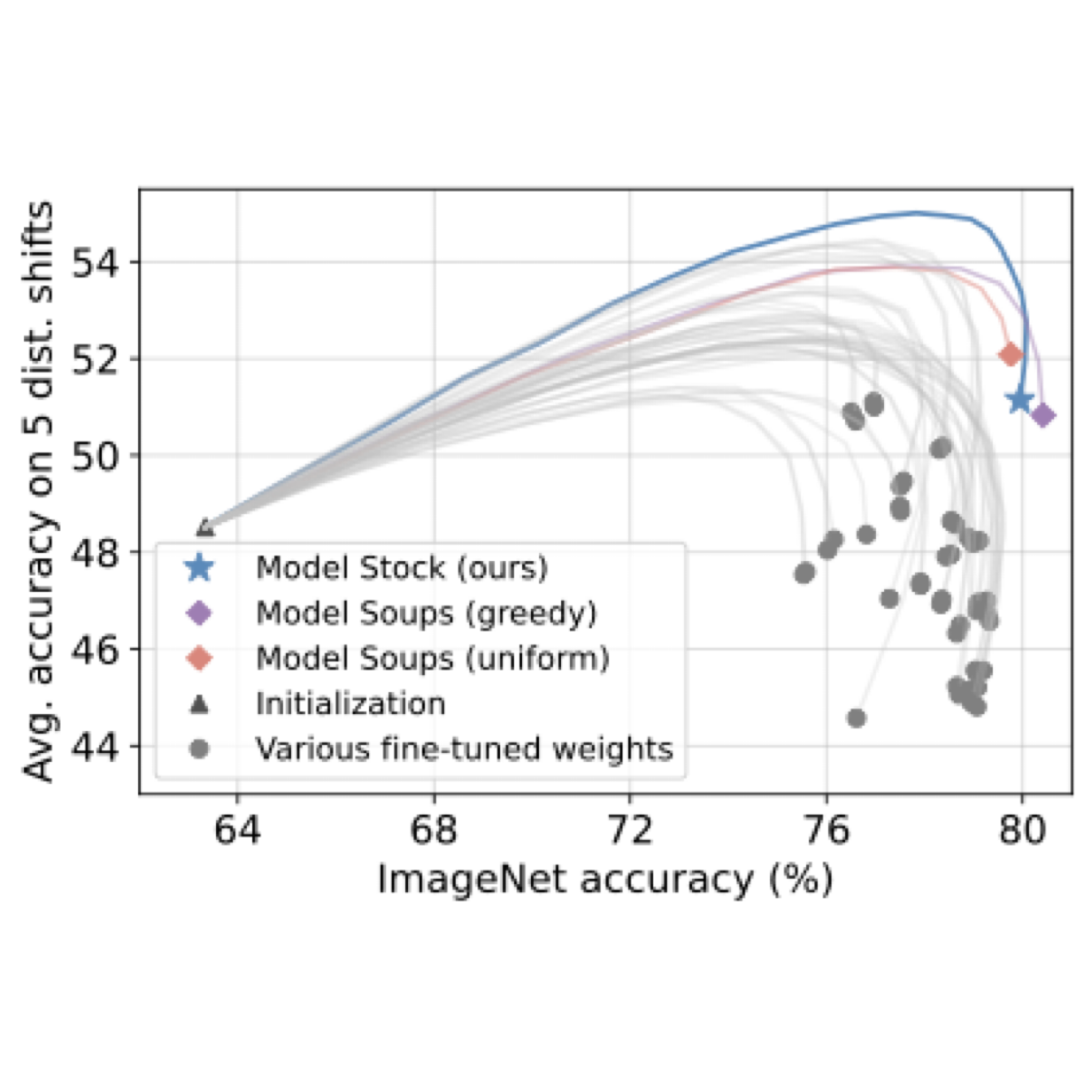
Dong-Hwan Jang, Sangdoo Yun, Dongyoon Han ECCV, 2024 (Oral, Top 2.3% among submitted papers). arxiv / github / article (marktechpost) Our analysis reveals that fine-tuned weights reside on a thin shell in the weight space, maintaining nearly constant layer-wise angles and norms. By leveraging the geometric link between center proximity and performance, we propose an efficient merging method that approximates the weight center with only two models—achieving superior ID/OOD performance at 24x less cost than Model Soup. |
|
Taehoon Kim, Dong-Hwan Jang, Bohyung Han CVPR Workshop on Continual Learning in Computer Vision, 2024 We introduce Merge-and-Bound (M&B), an innovative approach for Class Incremental Learning that optimizes model weights through two merging techniques: inter-task and intra-task weight merging, alongside a bounded update to prevent catastrophic forgetting. Without altering architectures or objectives, M&B integrates into existing methods, showing superior performance on CIL benchmarks against top competitors. |
|
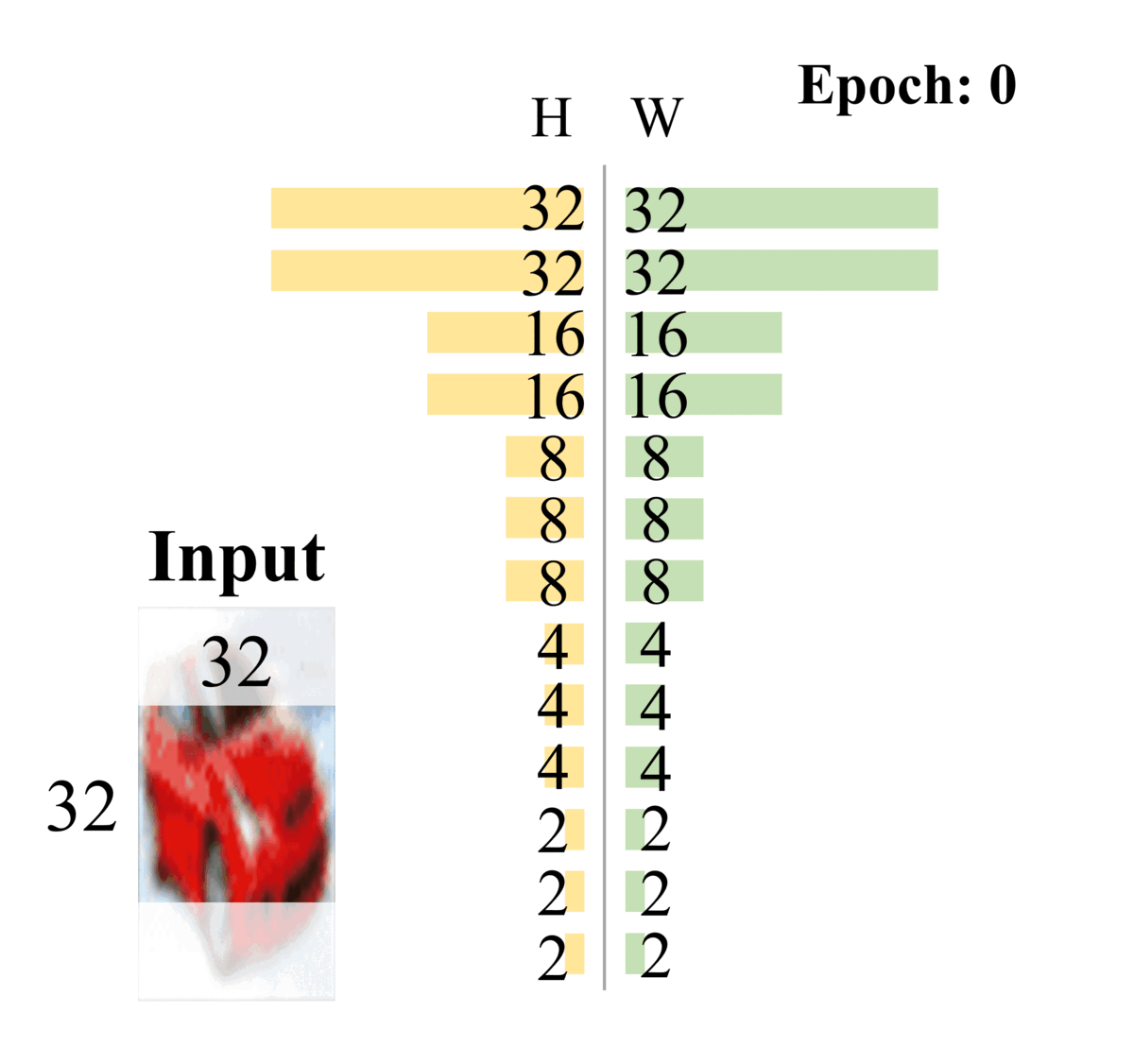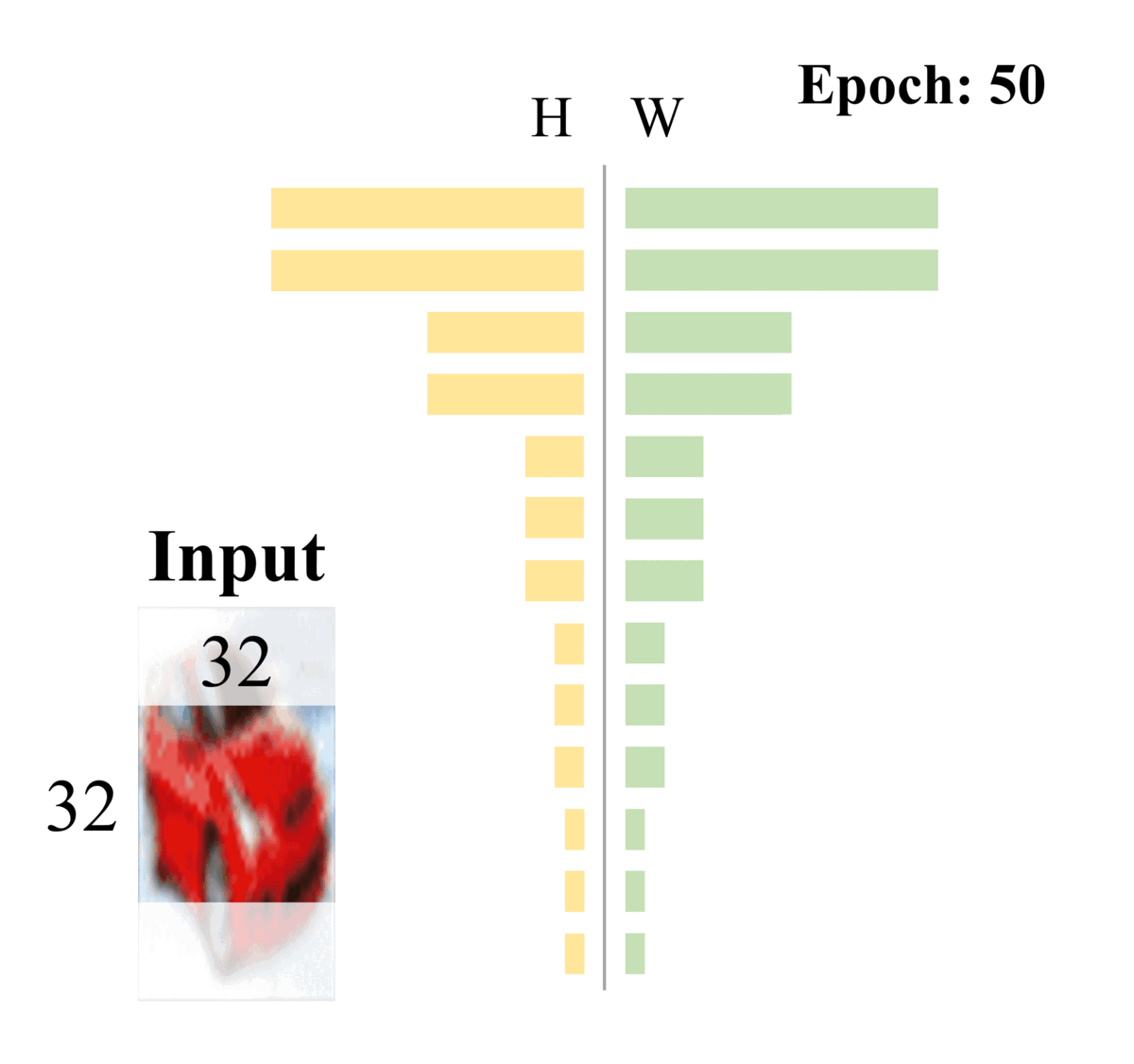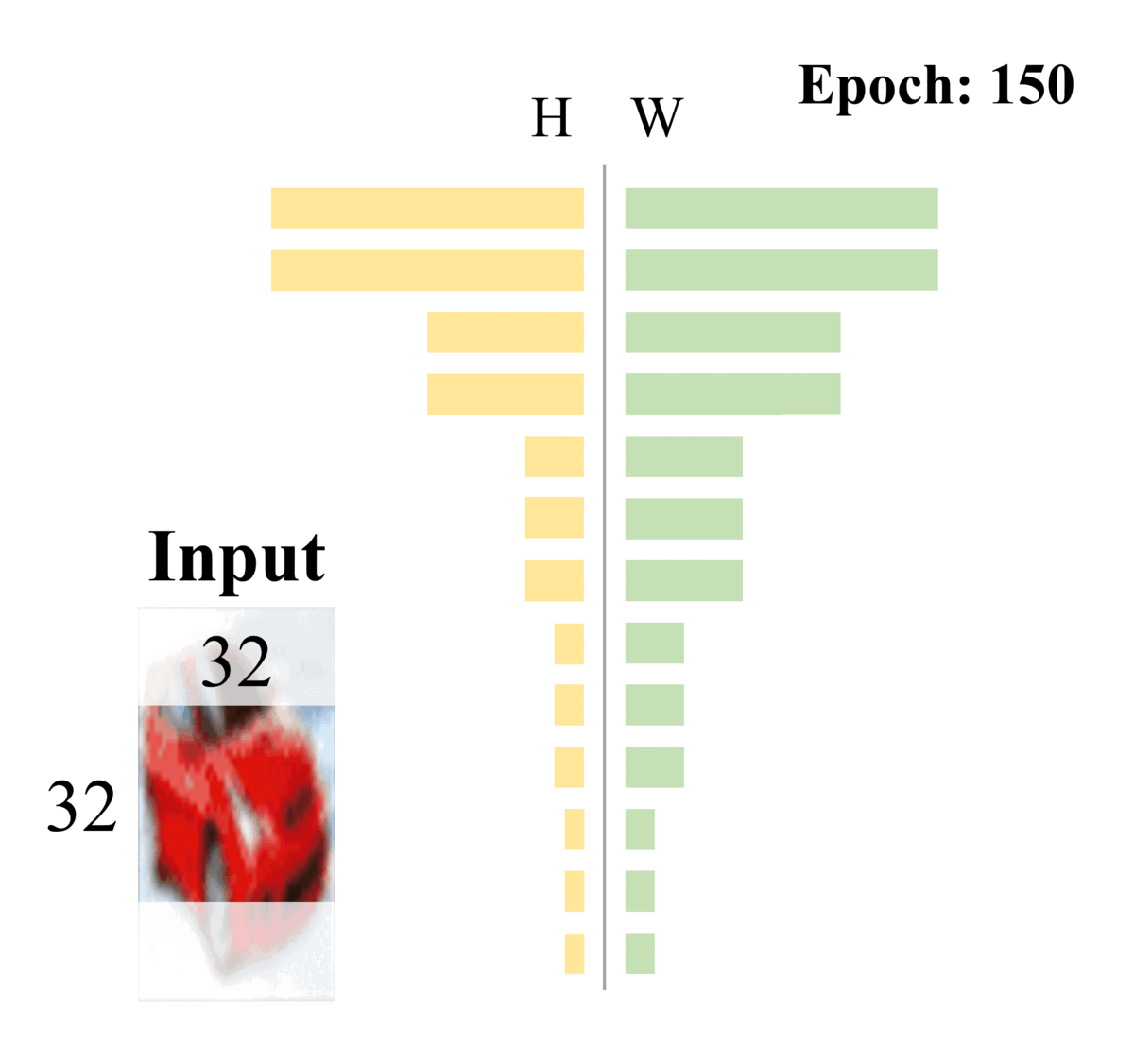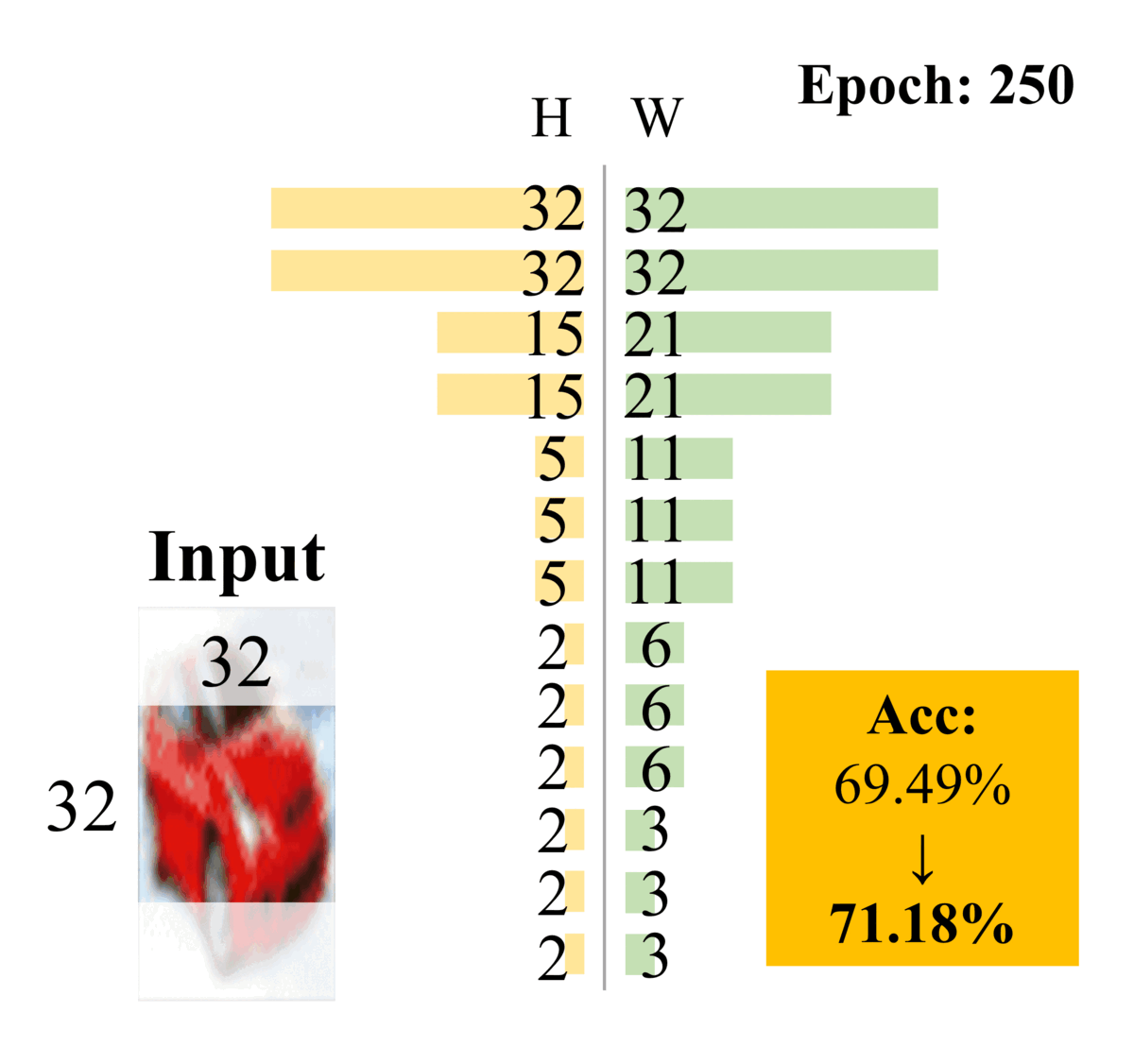
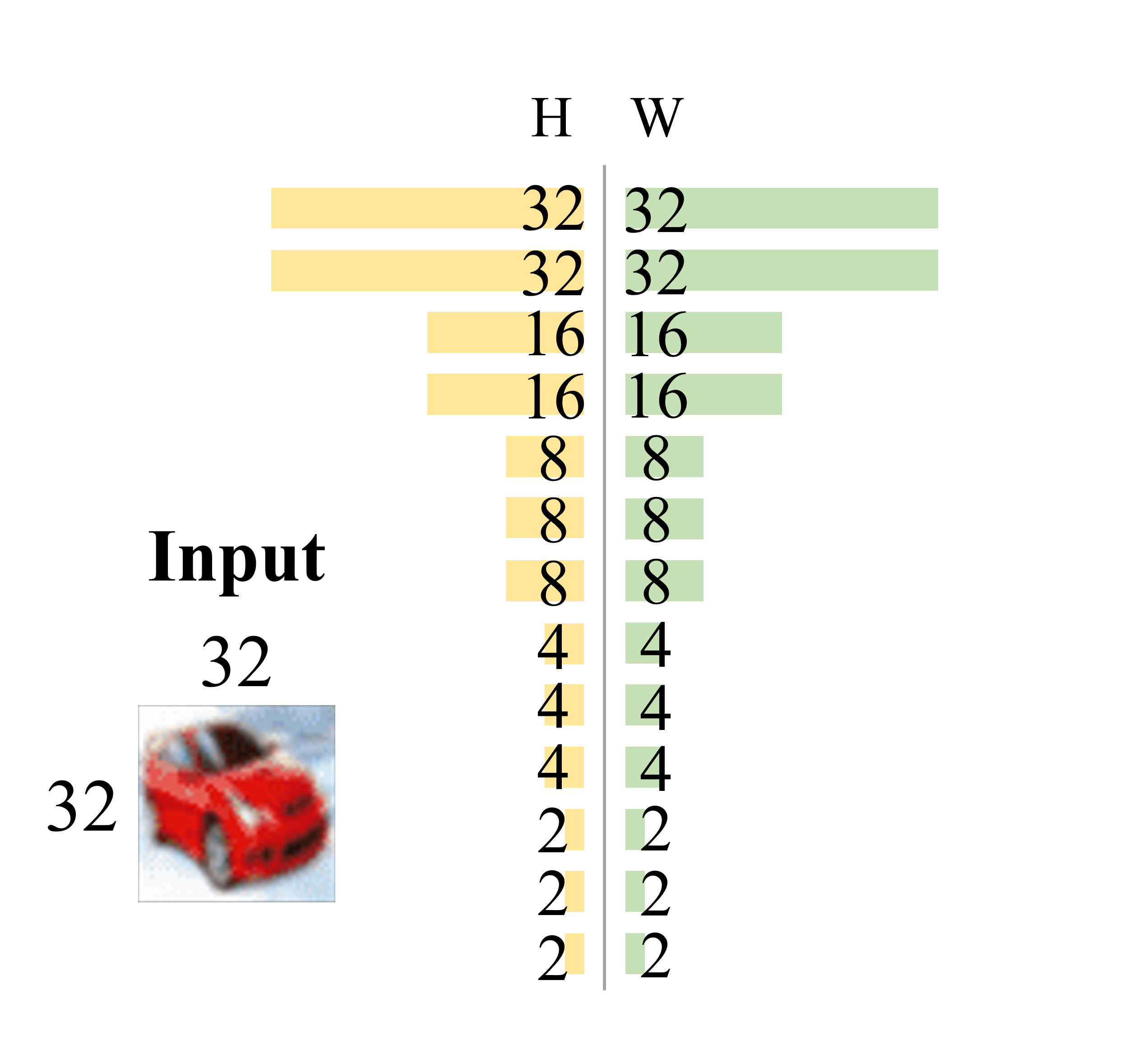
Dong-Hwan Jang, Sanghyeok Chu, Joonhyuk Kim, Bohyung Han CVPR, 2022 We propose DynOPool, a learnable pooling layer that finds the optimal scale factors and receptive fields of intermediate feature maps. While fixed pooling operators often result in suboptimal receptive fields by ignoring dataset-specific characteristics, DynOPool enables data-driven resolution scaling, achieving up to a 5.6%p accuracy gain on fine-grained recognition (FGVC-Aircraft) and 33% model compression on ImageNet without accuracy loss. It adapts feature map sizes and shapes for enhanced accuracy and efficiency in tasks like image classification and semantic segmentation. |

|
Jimi Kim*, Seojin Jang*, Joong Kun Lee*, Dong-Hwan Jang* (* equal contributions) NeurIPS Workshop on Causal Discovery & Causality-Inspired Machine Learning, 2020 project page / article (korean) (auto-translated) We present DS4C South Korea Patient, Policy, and Provincial data (DS4C-PPP dataset). The dataset contains comprehensive data that could be used for causal analysis, such as per-patient symptom onset and confirmed date, travel frequency, hospital accessibility, and 61 preventative policies enacted in South Korea. |
 
|
We propose spatially-variant motion deblur network based on the implicit neural representation. A spatially-variant deblurring network takes deformed features and their offsets as inputs. U.S. Patent Application Number: 17/973,809 (in progress) |
|
We propose a novel framework of the dynamic spatially-adaptive modulation for image dehazing. The proposed algorithm introduces a selection module that conditionally determine the necessary modulation pathways in a bottom-up manner by providing a loss function optimizing both accuracy and efficiency. |

|
We adaptively find the appropriate number of the residual blocks according to the severity and distortion type of the input in universal image restoration task. |
|
|